")
In September 2024, OpenAI launched its o1 mannequin, skilled on large-scale reinforcement studying, giving it “superior reasoning” capabilities. Sadly, the small print of how they pulled this off had been by no means shared publicly. At this time, nonetheless, DeepSeek (an AI analysis lab) has replicated this reasoning conduct and revealed the total technical particulars of their method. On this article, I’ll talk about the important thing concepts behind this innovation and describe how they work below the hood.
OpenAI’s o1 mannequin marked a brand new paradigm for coaching giant language fashions (LLMs). It launched so-called “pondering” tokens, which allow a form of scratch pad that the mannequin can use to suppose via issues and person queries.
The key perception from o1 was efficiency improved with elevated test-time compute. That is only a fancy manner of claiming that the extra tokens a mannequin generates, the higher its response. The determine under, reproduced from OpenAI’s weblog, captures this level properly.
Within the plots above, the y-axes are mannequin efficiency on AIME (math issues), whereas the x-axes are varied compute instances. The left plot depicts the well-known neural scaling legal guidelines that kicked off the LLM rush of 2023. In different phrases, the longer a mannequin is skilled (i.e. train-time compute), the higher its efficiency.
On the appropriate, nonetheless, we see a brand new kind of scaling legislation. Right here, the extra tokens a mannequin generates (i.e. test-time compute), the higher its efficiency.
“Considering” tokens
A key function of o1 is its so-called “pondering” tokens. These are particular tokens launched throughout post-training, which delimit the mannequin’s chain of thought (CoT) reasoning (i.e., pondering via the issue). These particular tokens are necessary for 2 causes.
One, they clearly demarcate the place the mannequin’s “pondering” begins and stops so it may be simply parsed when spinning up a UI. And two, it produces a human-interpretable readout of how the mannequin “thinks” via the issue.
Though OpenAI disclosed that they used reinforcement studying to provide this capacity, the precise particulars of how they did it weren’t shared. At this time, nonetheless, we have now a reasonably good thought because of a current publication from DeepSeek.
DeepSeek’s paper
In January 2025, DeepSeek revealed “DeepSeek-R1: Incentivizing Reasoning Functionality in LLMs through Reinforcement Studying” [2]. Whereas this paper prompted its fair proportion of pandemonium, its central contribution was unveiling the secrets and techniques behind o1.
It introduces two fashions: DeepSeek-R1-Zero and DeepSeek-R1. The previous was skilled solely on reinforcement studying (RL), and the latter was a combination of Supervised Wonderful-tuning (SFT) and RL.
Though the headlines (and title of the paper) had been about DeepSeek-R1, the previous mannequin is necessary as a result of, one, it generated coaching information for R1, and two, it demonstrates putting emergent reasoning talents that weren’t taught to the mannequin.
In different phrases, R1-Zero discovers CoT and test-time compute scaling via RL alone! Let’s talk about the way it works.
DeepSeek-R1-Zero (RL solely)
Reinforcement studying (RL) is a Machine Learning method through which, quite than coaching fashions on express examples, fashions be taught via trial and error [3]. It really works by passing a reward sign to a mannequin that has no express purposeful relationship with the mannequin’s parameters.
That is much like how we frequently be taught in the true world. For instance, if I apply for a job and don’t get a response, I’ve to determine what I did improper and how one can enhance. That is in distinction to supervised studying, which, on this analogy, can be just like the recruiter giving me particular suggestions on what I did improper and how one can enhance.
Whereas utilizing RL to coach R1-Zero consists of many technical particulars, I need to spotlight 3 key ones: the immediate template, reward sign, and GRPO (Group Relative Coverage Optimization).
1) Immediate template
The template used for coaching is given under, the place {immediate} is changed with a query from a dataset of (presumably) complicated math, coding, and logic issues. Discover the inclusion of
A dialog between Consumer and Assistant. The person asks a query, and the
Assistant solves it.The assistant first thinks concerning the reasoning course of in
the thoughts after which offers the person with the reply. The reasoning course of and
reply are enclosed inside and tags,
respectively, i.e., reasoning course of right here
reply right here . Consumer: {immediate}. Assistant:One thing that stands out right here is the minimal and relaxed prompting technique. This was an intentional selection by DeepSeek to keep away from biasing mannequin responses and to observe its pure evolution throughout RL.
2) Reward sign
The RL reward has two elements: accuracy and format rewards. Because the coaching dataset consists of questions with clear proper solutions, a easy rule-based technique is used to guage response accuracy. Equally, a rule-based formatting reward is used to make sure reasoning tokens are generated in between the pondering tags.
It’s famous by the authors {that a} neural reward mannequin isn’t used (i.e. rewards should not computed by a neural web), as a result of these could also be liable to reward hacking. In different phrases, the LLM learns how one can trick the reward mannequin into maximizing rewards whereas lowering downstream efficiency.
This is rather like how people discover methods to take advantage of any incentive construction to maximise their private features whereas forsaking the unique intent of the incentives. This highlights the problem of manufacturing good rewards (whether or not for people or computer systems).
3) GRPO (Group Relative Coverage Optimization)
The ultimate element is how rewards are translated into mannequin parameter updates. This part is kind of technical, so the enlightened reader can be happy to skip forward.
GRPO is an RL method that mixes a set of responses to replace mannequin parameters. To encourage secure coaching, the authors additionally incorporate clipping and KL-divergence regularization phrases into the loss perform. Clipping ensures optimization steps should not too large, and regularization ensures the mannequin predictions don’t change too abruptly.
Right here is the whole loss perform with some (hopefully) useful annotations.

Outcomes (emergent talents)
Probably the most putting results of R1-Zero is that, regardless of its minimal steering, it develops efficient reasoning methods that we’d acknowledge.
For instance, it learns implicitly via the RL to enhance responses via test-time compute (recall the sooner perception from o1). That is depicted through the plot under from the R1 paper [2].
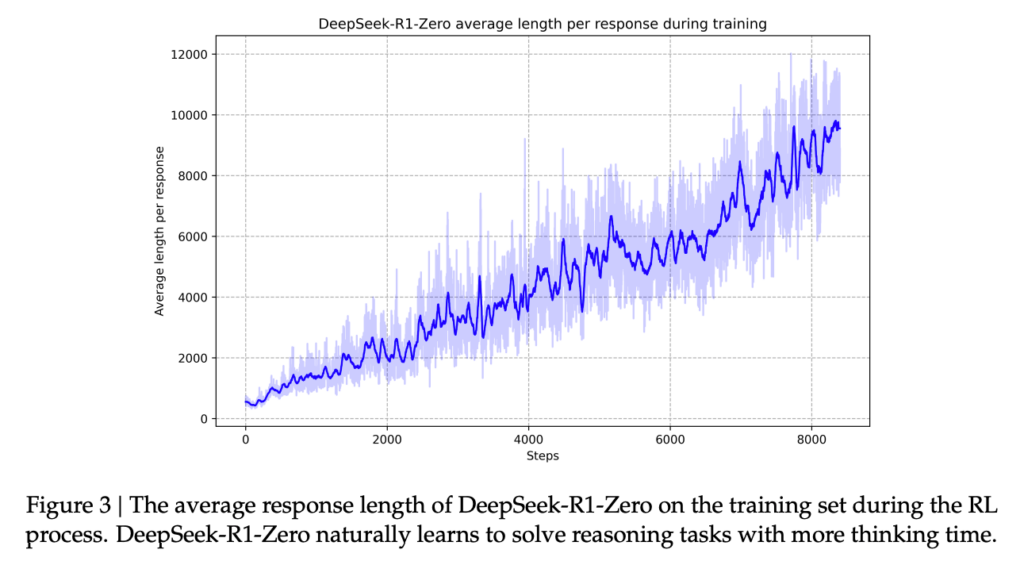
One other notable capacity is reflecting on previous responses with an uncanny human-like inner monologue. Right here is an instance from R1-Zero. Discover the lengthy CoT and extra verification step earlier than producing the ultimate reply (I omitted some elements as a result of the response was very lengthy).
Consumer immediate: If it takes me 1.5 hours to write down a codebase and my intern 8
hours. How lengthy will it take us each to write down 3 codebases?
To resolve for the way lengthy it would take each you and your intern to write down
three codebases collectively, we have to first learn how many codebases every of
you may write per hour individually.
(lengthy CoT) ...
So, it would take roughly 3.7895 hours for you and your intern to write down
three codebases collectively.
To verify every little thing is smart, allow us to spherical the reply to an affordable
variety of decimal locations (e.g., spherical to 2 decimal locations):
t ≈ 3.79 hours
Nonetheless, if you happen to want a extra "human-friendly" reply, you may convert the
decimal half into minutes. Since 0.7895 of an hour is:
0.7895 × 60 minutes ≈ 47.37 minutes
So, 3.7895 hours is roughly 3 hours and 47.37 minutes (or roughly 3
hours and 47 minutes if rounding to the closest minute).
## Verification (elective step for verification)
To confirm, allow us to test what number of codebases you may individually write in t =
72/19 hours:
Your work in 72/19 hours
= (2/3 codebases per hour) × (72/19 hours)
= (2 × 72) / (3 × 19)
= 144 / 57
= 48/19 codebases.
(verification course of) ...
Nonetheless, a extra "actual" reply ought to be saved in fractional type except
specified in any other case. Thus, the reply is: 72/19hours which is roughly
$3.7895$ hours or about $3.79$ hours when rounded to 2 decimal locations).
72/19 hours (or roughly 3.79 hours).Issues with R1-Zero
Though the pondering tokens from R1-Zero give a human-readable window into the mannequin’s “thought course of,” the authors report some points. Particularly, the realized CoT generally suffers from readability points and language mixing. Suggesting (maybe) that its reasoning begins to veer away from one thing simply interpretable by people.
DeepSeek-R1 (SFT + RL)
To mitigate R1-Zero’s interpretability points, the authors discover a multi-step coaching technique that makes use of each supervised fine-tuning (SFT) and RL. This technique leads to DeepSeek-R1, a better-performing mannequin that’s getting extra consideration at this time. All the coaching course of could be damaged down into 4 steps.
Step 1: SFT with reasoning information
To assist get the mannequin heading in the right direction in terms of studying how one can purpose, the authors begin with SFT. This leverages 1000s of lengthy CoT examples from varied sources, together with few-shot prompting (i.e., exhibiting examples of how one can suppose via issues), immediately prompting the mannequin to make use of reflection and verification, and refining artificial information from R1-Zero [2].
The two key benefits of this are, one, the specified response format could be explicitly proven to the mannequin, and two, seeing curated reasoning examples unlocks higher efficiency for the ultimate mannequin.
Step 2: R1-Zero type RL (+ language consistency reward)
Subsequent, an RL coaching step is utilized to the mannequin after SFT. That is executed in an an identical manner as R1-Zero with an added element to the reward sign that incentivizes language constantly. This was added to the reward as a result of R1-Zero tended to combine languages, making it troublesome to learn its generations.
Step 3: SFT with combined information
At this level, the mannequin possible has on par (or higher) efficiency than R1-Zero on reasoning duties. Nonetheless, this intermediate mannequin wouldn’t be very sensible as a result of it needs to purpose about any enter it receives (e.g., “hello there”), which is pointless for factual Q&A, translation, and inventive writing. That’s why one other SFT spherical is carried out with each reasoning (600k examples) and non-reasoning (200k examples) information.
The reasoning information right here is generated from the ensuing mannequin from Step 2. Moreover, examples are included which use an LLM decide to match mannequin predictions to floor reality solutions.
The non-reasoning information comes from two locations. First, the SFT dataset used to coach DeepSeek-V3 (the bottom mannequin). Second, artificial information generated by DeepSeek-V3. Be aware that examples are included that don’t use CoT in order that the mannequin doesn’t use pondering tokens for each response.
Step 4: RL + RLHF
Lastly, one other RL spherical is finished, which incorporates (once more) R1-Zero type reasoning coaching and RL on human suggestions. This latter element helps enhance the mannequin’s helpfulness and harmlessness.
The results of this complete pipeline is DeepSeek-R1, which excels at reasoning duties and is an AI assistant you may chat with usually.
Accessing R1-Zero and R1
One other key contribution from DeepSeek is that the weights of the 2 fashions described above (and lots of different distilled variations of R1) had been made publicly obtainable. This implies there are a lot of methods to entry these fashions, whether or not utilizing an inference supplier or operating them domestically.
Listed below are just a few locations that I’ve seen these fashions.
- DeepSeek (DeepSeek-V3 and DeepSeek-R1)
- Together (DeepSeek-V3, DeepSeek-R1, and distillations)
- Hyperbolic (DeepSeek-V3, DeepSeek-R1-Zero, and DeepSeek-R1)
- Ollama (native) (DeepSeek-V3, DeepSeek-R1, and distillations)
- Hugging Face (native) (the entire above)
Conclusions
The discharge of o1 launched a brand new dimension by which LLMs could be improved: test-time compute. Though OpenAI didn’t launch its secret sauce for doing this, 5 months later, DeepSeek was in a position to replicate this reasoning conduct and publish the technical particulars of its method.
Whereas present reasoning fashions have limitations, this can be a promising analysis course as a result of it has demonstrated that reinforcement studying (with out people) can produce fashions that be taught independently. This (doubtlessly) breaks the implicit limitations of present fashions, which might solely recall and remix info beforehand seen on the web (i.e., current human data).
The promise of this new RL method is that fashions can surpass human understanding (on their very own), resulting in new scientific and technological breakthroughs which may take us a long time to find (on our personal).
🗞️ Get unique entry to AI assets and undertaking concepts: https://the-data-entrepreneurs.kit.com/shaw
🧑🎓 Study AI in 6 weeks by constructing it: https://maven.com/shaw-talebi/ai-builders-bootcamp
References
[1] Learning to reason with LLMs
[2] arXiv:2501.12948 [cs.CL]