
Initially revealed on HuggingFace
TL;DR
We current LettuceDetect, a light-weight hallucination detector for Retrieval-Augmented Era (RAG) pipelines. It’s an encoder-based mannequin constructed on ModernBERT, launched underneath the MIT license with ready-to-use Python packages and pretrained fashions.
- What: LettuceDetect is a token-level detector that flags unsupported segments in LLM solutions. 🥬
- How: Skilled on RAGTruth (18k examples), leveraging ModernBERT for context lengths as much as 4k tokens. 🚀
- Why: It addresses (1) the context-window limits in prior encoder-only fashions, and (2) the excessive compute prices of LLM-based detectors. ⚖️
- Highlights:
- Beats prior encoder-based fashions (e.g., Luna) on RAGTruth. ✅
- Surpasses fine-tuned Llama-2-13B [2] at a fraction of the dimensions, and is very environment friendly at inference. ⚡️
- Completely open-source with an MIT license. 🔓
LettuceDetect retains your RAG framework contemporary by recognizing rotten components of your LLM’s outputs. 😊
Fast hyperlinks
Why LettuceDetect?
Giant Language Fashions (LLMs) have made appreciable developments in NLP duties, like GPT-4 [4], the Llama-3 fashions [5], or Mistral [6] (and plenty of extra). Regardless of the success of LLMs, Hallucinations stay a key impediment deploying LLMs in high-stakes situations (resembling in healthcare or authorized) [7,8].
Retrieval-Augmented Era (RAG) makes an attempt to mitigate hallucinations by grounding an LLM’s responses in retrieved paperwork, offering exterior information that the mannequin can reference [9]. However regardless that RAG is a strong technique to cut back hallucinations, LLMs nonetheless endure from hallucinations in these settings [1]. Hallucinations are data within the output that’s nonsensical, factually incorrect, or inconsistent with the retrieved context [8]. Ji et al. [10] categorizes hallucinations into:
- Intrinsic hallucinations: Stemming from the mannequin’s preexisting inside information.
- Extrinsic hallucinations: Occurring when the reply conflicts with the context or references supplied
Whereas RAG approaches can mitigate intrinsic hallucinations, they don’t seem to be resistant to extrinsic hallucinations. Solar et al. [11] confirmed that fashions are likely to prioritize their intrinsic information over the exterior context. As LLMs stay liable to hallucinations, their functions in essential domains e.g. medical or authorized, will be nonetheless flawed.
Present options for hallucination detection
Present options for hallucination detection will be categorized into totally different classes based mostly on the strategy they take:
- Immediate-based detectors These strategies (e.g., RAGAS, Trulens, ARES) usually leverage zero-shot or few-shot prompts to detect hallucinations. They typically depend on giant LLMs (like GPT-4) and make use of methods resembling SelfCheckGPT [12], LM vs. LM [13], or Chainpoll [14]. Whereas typically efficient, they are often computationally costly as a result of repeated LLM calls.
- Positive-tuned LLM detectors Giant fashions (e.g., Llama-2, Llama-3) will be fine-tuned for hallucination detection [1,15]. This may yield excessive accuracy (as proven by the RAGTruth authors utilizing Llama-2-13B or the RAG-HAT work on Llama-3-8B) however is resource-intensive to coach and deploy. Inference prices additionally are typically excessive as a result of their dimension and slower speeds.
- Encoder-based detectors Fashions like Luna [2] depend on a BERT-style encoder (typically restricted to 512 tokens) for token-level classification. These strategies are usually extra environment friendly than operating a full LLM at inference however are constrained by brief context home windows and a spotlight mechanisms optimized for smaller inputs.
ModernBERT for lengthy context
ModernBERT [3] is a drop-in alternative for BERT and is a state-of-the-art encoder-only transformers structure that includes a number of fashionable design enhancements over the unique BERT mannequin such because it makes use of Rotary Positional Embeddings (RoPe) to deal with sequences of as much as 8,192 tokens, unpadding optimization to get rid of wasted computation on padding tokens, and GeGLU activation layers for enhanced expressiveness and alternating attention for extra environment friendly consideration computation.
LettuceDetect capitalizes on ModernBERT’s prolonged context window to construct a token-level classifier for hallucination detection. This strategy sidesteps many limitations of older BERT-based fashions (e.g., brief context bounds) and avoids the inference overhead of enormous LLM-based detectors. Our experiments present that LettuceDetect outperforms different encoder-based methods whereas remaining aggressive with fine-tuned LLM detectors at a fraction of their computational value.
Information
RAGTruth is the primary large-scale open-source (MIT License) benchmark particularly designed to judge hallucination detection in Retrieval-Augmented Era (RAG) settings. It comprises 18,000 annotated examples spanning a number of duties:
- Query answering (QA): Sampled from the MS MARCO dataset, the place as much as three paperwork are retrieved for every query, and an LLM is prompted to supply a solution.
- Information-to-text era: Primarily based on the Yelp Open Dataset, the place LLMs generate critiques for sampled companies.
- Information summarization: Makes use of random paperwork from CNN/DailyMail, prompting LLMs to supply summaries.
Every instance in RAGTruth consists of:
- A query and immediate,
- A number of reference passages or context paperwork,
- An LLM-generated response,
- Human annotations on the span degree indicating whether or not any a part of the reply is factually unsupported or contradictory to the reference passages.
Beneath is an illustrative pattern from RAGTruth, exhibiting an occasion of hallucination:
QUESTION
Tips on how to clarify quartiles?
REFERENCE
Passage 2:
Second quartile (Q2) which is extra generally generally known as median splits the information in half (50%).
Median divides the information right into a decrease half and an higher half.
Third quartile (Q3), often known as higher quartile, splits lowest 75% (or highest 25%) of information.
(…)
RESPONSE
The primary quartile (Q1) splits the bottom 25% of the information, whereas the second quartile (Q2) splits the information into two equal halves, with the median being the center worth of the decrease half. Lastly, the third quartile (Q3) splits the very best 75% of the information.
(…)
ANNOTATION
- Span: “highest 75%”
- Sort: Evident Battle
- Purpose:
- Unique textual content: “lowest 75% (or highest 25%)”
- Generative textual content: “highest 75%”
This instance showcases a RAGTruth annotation involving particular spans within the reply that battle with the reference passages, offering each the sort of hallucination (e.g., Evident Battle) and a human-readable rationale. Our technique solely makes use of binary annotations and doesn’t use the kind of hallucination annotations.
Technique
A high-level depiction of LettuceDetect. Right here, an instance Query, Context, and Reply triplet is processed. First, the textual content is tokenized, after which LettuceDetect performs token-level classification. Tokens from each the query and context are masked (indicated by the purple line within the determine) to exclude them from the loss perform. Every token within the reply receives a chance indicating whether or not it’s hallucinated or supported. For span-level detection, we merge consecutive tokens with hallucination possibilities above 0.5 right into a single predicted span.
We practice ModernBERT-base and ModernBERT-large variants as token-classification fashions on the RAGTruth dataset. The enter to the mannequin is a concatenation of Context, Query, and Reply segments, with specialised tokens ([CLS]) (for the context) and ([SEP]) (as separators). We restrict the sequence size to 4,096 tokens for computational feasibility, although ModernBERT can theoretically deal with as much as 8,192 tokens.
Tokenization and information processing
- Tokenizer: We make use of AutoTokenizer from the Transformers library to deal with subword Tokenization, inserting [CLS] and [SEP] appropriately.
- Labeling:
- Context/query tokens are masked (i.e., assigned a label of -100 in PyTorch) in order that they don’t contribute to the loss.
- Every reply token receives a label of 0 (supported) or 1 (hallucinated).
Mannequin structure
Our fashions construct on Hugging Face’s AutoModelForTokenClassification, utilizing ModernBERT because the encoder and a classification head on prime. In contrast to some earlier encoder-based approaches (e.g., ones pre-trained on NLI duties), our technique makes use of solely ModernBERT with no further pretraining stage.
Coaching configuration
- Optimizer: AdamW, with a studying price of 1 * 10^-5 and weight decay of 0.01.
- {Hardware}: Single NVIDIA A100 GPU.
- Epochs: 6 whole coaching epochs.
- Batching:
- Batch dimension of 8,
- Information loading with PyTorch DataLoader (shuffling enabled),
- Dynamic padding by way of DataCollatorForTokenClassification to deal with variable-length sequences effectively.
Throughout coaching, we monitor token-level F1 scores on a validation break up, saving checkpoints utilizing the safetensors format. As soon as coaching is full, we add the best-performing fashions to Hugging Face for public entry.
At inference time, the mannequin outputs a chance of hallucination for every token within the reply. We mixture consecutive tokens exceeding a 0.5 threshold to supply span-level predictions, indicating precisely which segments of the reply are prone to be hallucinated. The determine above illustrates this workflow.
Subsequent, we offer a extra detailed analysis of the mannequin’s efficiency.
Outcomes
We consider our fashions on the RAGTruth check set throughout all process sorts (Query Answering, Information-to-Textual content, and Summarization). For every instance, RAGTruth consists of manually annotated spans indicating hallucinated content material.
Instance-level outcomes
We first assess the example-level query: Does the generated reply include any hallucination in any respect? Our giant mannequin (lettucedetect-large-v1) attains an total F1 rating of 79.22%, surpassing:
- GPT-4 (63.4%),
- Luna (65.4%) (the earlier cutting-edge encoder-based mannequin),
- Positive-tuned Llama-2-13B (78.7%) as offered within the RAGTruth paper.
It’s second solely to the fine-tuned Llama-3-8B from the RAG-HAT paper [15] (83.9%), however LettuceDetect is considerably smaller and quicker to run. In the meantime, our base mannequin (lettucedetect-base-v1) stays extremely aggressive whereas utilizing fewer parameters.
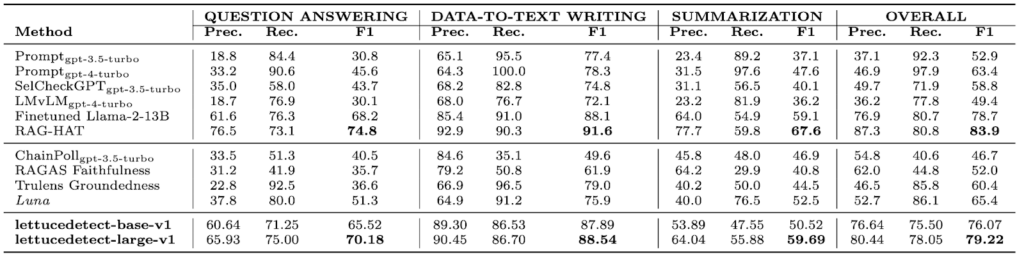
Above is a comparability desk illustrating how LettuceDetect aligns towards each prompt-based strategies (e.g., GPT-4) and different encoder-based options (e.g., Luna). Total, lettucedetect-large-v1 and lettucedect-base-v1 are very performant fashions, whereas being very efficient in inference settings.
Span-level outcomes
Past detecting if a solution comprises hallucinations, we additionally look at LettuceDetect’s means to determine the actual spans of unsupported content material. Right here, LettuceDetect achieves state-of-the-art outcomes amongst fashions which have reported span-level efficiency, considerably outperforming the fine-tuned Llama-2-13B mannequin from the RAGTruth paper [1] and different baselines.

Most strategies, like RAG-HAT [15], don’t report span-level metrics, so we don’t examine to them right here.
Inference effectivity
Each lettucedetect-base-v1 and lettucedetect-large-v1 require fewer parameters than typical LLM-based detectors (e.g., GPT-4 or Llama-3-8B) and may course of 30–60 examples per second on a single NVIDIA A100 GPU. This makes them sensible for industrial workloads, real-time user-facing methods, and resource-constrained environments.
Total, these outcomes present that LettuceDetect has steadiness: it achieves close to state-of-the-art accuracy at a fraction of the dimensions and value in comparison with giant LLM-based judges, whereas providing exact, token-level hallucination detection.
Get going
Set up the package deal:
pip set up lettucedetectThen, you should use the package deal as follows:
from lettucedetect.fashions.inference import HallucinationDetector
# For a transformer-based strategy:
detector = HallucinationDetector(
technique="transformer", model_path="KRLabsOrg/lettucedect-base-modernbert-en-v1"
)
contexts = ["France is a country in Europe. The capital of France is Paris. The population of France is 67 million.",]
query = "What's the capital of France? What's the inhabitants of France?"
reply = "The capital of France is Paris. The inhabitants of France is 69 million."
# Get span-level predictions indicating which components of the reply are thought of hallucinated.
predictions = detector.predict(context=contexts, query=query, reply=reply, output_format="spans")
print("Predictions:", predictions)
# Predictions: [{'start': 31, 'end': 71, 'confidence': 0.9944414496421814, 'text': ' The population of France is 69 million.'}]Conclusion
We launched LettuceDetect, a light-weight and environment friendly framework for hallucination detection in RAG methods. By using ModernBERT’s prolonged context capabilities, our fashions obtain robust efficiency on the RAGTruth benchmark whereas retaining excessive inference effectivity. This work lays the groundwork for future analysis instructions, resembling increasing to further datasets, supporting a number of languages, and exploring extra superior architectures. Even at this stage, LettuceDetect demonstrates that efficient hallucination detection will be achieved utilizing lean, purpose-built encoder-based fashions.
Quotation
Should you discover this work helpful, please cite it as follows:
@misc{Kovacs:2025,
title={LettuceDetect: A Hallucination Detection Framework for RAG Purposes},
writer={Ádám Kovács and Gábor Recski},
12 months={2025},
eprint={2502.17125},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.17125},
}Additionally, in case you use our code, please don’t overlook to offer us a star ⭐ on our GitHub repository here.
References
[1] Niu et al., 2024, RAGTruth: A Dataset for Hallucination Detection in Retrieval-Augmented Generation
[3] ModernBERT: A Modern BERT Model for Long-Context Processing
[4] GPT-4 report
[5] Llama-3 report
[6] Mistral 7B
[7] Kaddour et al., 2023, Challenges and Applications of Large Language Models
[9] Gao et al., 2024, Retrieval-Augmented Generation for Large Language Models: A Survey
[10] Ji et al., 2023, Survey of Hallucination in Natural Language Generation
[13] Cohen et al., 2023, LM vs LM: Detecting Factual Errors via Cross Examination
[14] Friel et al., 2023, Chainpoll: A high efficacy method for LLM hallucination detection