
This put up was co-authored with Rafael Guedes.
Introduction
Conventional fashions can solely course of a single sort of information, reminiscent of textual content, photos, or tabular knowledge. Multimodality is a trending idea within the AI analysis group, referring to a mannequin’s potential to be taught from a number of kinds of knowledge concurrently. This new know-how (probably not new, however considerably improved in the previous few months) has quite a few potential functions that may rework the consumer expertise of many merchandise.
One good instance can be the brand new approach engines like google will work sooner or later, the place customers can enter queries utilizing a mixture of modalities, reminiscent of textual content, photos, audio, and so on. One other instance might be bettering AI-powered buyer assist programs for voice and textual content inputs. In e-commerce, they’re enhancing product discovery by permitting customers to look utilizing photos and textual content. We’ll use the latter as our case research on this article.
The frontier AI analysis labs are delivery a number of fashions that assist a number of modalities each month. CLIP and DALL-E by OpenAI and BLIP-2 by Salesforce mix picture and textual content. ImageBind by Meta expanded the a number of modality idea to 6 modalities (textual content, audio, depth, thermal, picture, and inertial measurement models).
On this article, we are going to discover BLIP-2 by explaining its structure, the best way its loss operate works, and its coaching course of. We additionally current a sensible use case that mixes BLIP-2 and Gemini to create a multimodal trend search agent that may help clients find the most effective outfit based mostly on both textual content or textual content and picture prompts.
As all the time, the code is out there on our GitHub.
BLIP-2: a multimodal mannequin
BLIP-2 (Bootstrapped Language-Picture Pre-Coaching) [1] is a vision-language mannequin designed to resolve duties reminiscent of visible query answering or multimodal reasoning based mostly on inputs of each modalities: picture and textual content. As we are going to see under, this mannequin was developed to deal with two predominant challenges within the vision-language area:
- Scale back computational price utilizing frozen pre-trained visible encoders and LLMs, drastically lowering the coaching assets wanted in comparison with a joint coaching of imaginative and prescient and language networks.
- Enhancing visual-language alignment by introducing Q-Former. Q-Former brings the visible and textual embeddings nearer, resulting in improved reasoning job efficiency and the power to carry out multimodal retrieval.
Structure
The structure of BLIP-2 follows a modular design that integrates three modules:
- Visible Encoder is a frozen visible mannequin, reminiscent of ViT, that extracts visible embeddings from the enter photos (that are then utilized in downstream duties).
- Querying Transformer (Q-Former) is the important thing to this structure. It consists of a trainable light-weight transformer that acts as an intermediate layer between the visible and language fashions. It’s answerable for producing contextualized queries from the visible embeddings in order that they are often processed successfully by the language mannequin.
- LLM is a frozen pre-trained LLM that processes refined visible embeddings to generate textual descriptions or solutions.
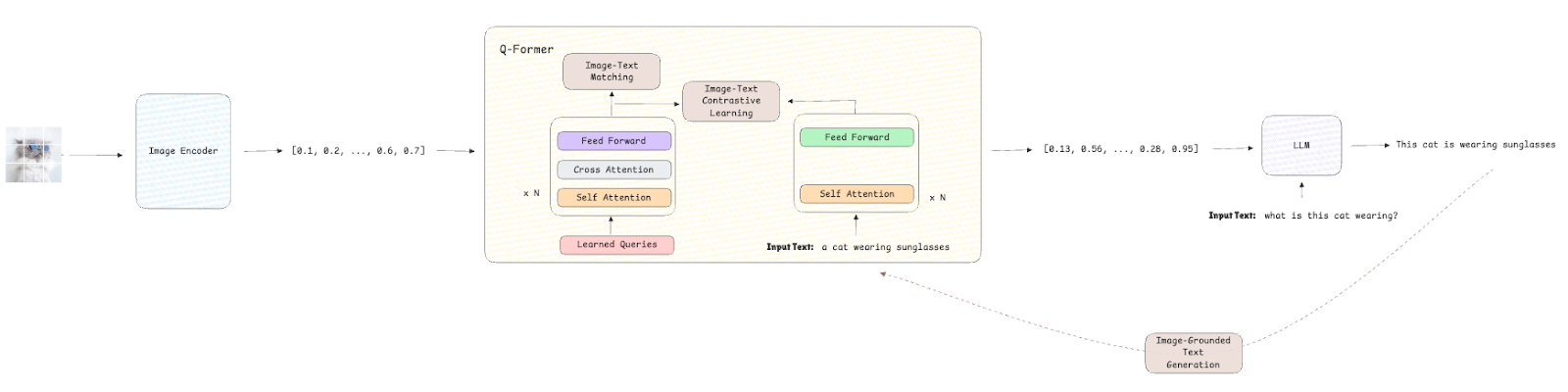
Loss Capabilities
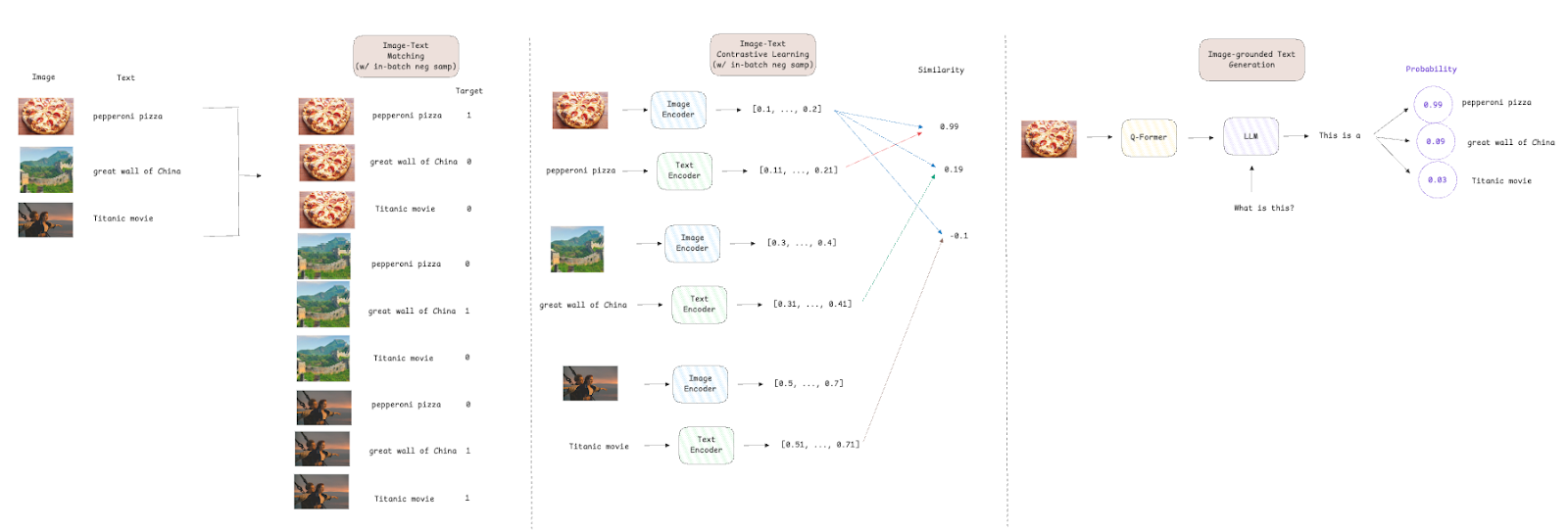
BLIP-2 has three loss capabilities to coach the Q-Former module:
- Picture-text contrastive loss [2] enforces the alignment between visible and textual content embeddings by maximizing the similarity of paired image-text representations whereas pushing aside dissimilar pairs.
- Picture-text matching loss [3] is a binary classification loss that goals to make the mannequin be taught fine-grained alignments by predicting whether or not a textual content description matches the picture (constructive, i.e., goal=1) or not (unfavourable, i.e., goal=0).
- Picture-grounded textual content technology loss [4] is a cross-entropy loss utilized in LLMs to foretell the likelihood of the following token within the sequence. The Q-Former structure doesn’t permit interactions between the picture embeddings and the textual content tokens; subsequently, the textual content should be generated based mostly solely on the visible info, forcing the mannequin to extract related visible options.
For each image-text contrastive loss and image-text matching loss, the authors used in-batch unfavourable sampling, which signifies that if we have now a batch dimension of 512, every image-text pair has one constructive pattern and 511 unfavourable samples. This method will increase effectivity since unfavourable samples are taken from the batch, and there’s no want to look all the dataset. It additionally gives a extra numerous set of comparisons, resulting in a greater gradient estimation and quicker convergence.
Coaching Course of
The coaching of BLIP-2 consists of two levels:
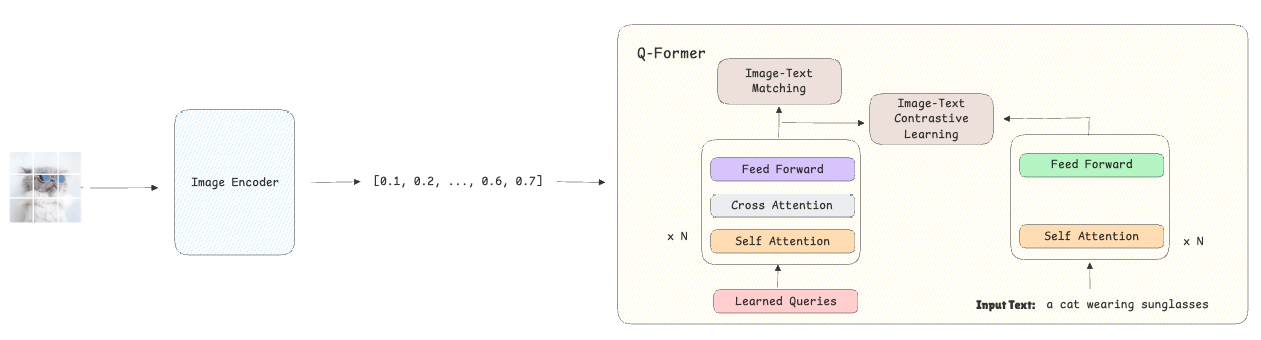
Stage 1 – Bootstrapping visual-language illustration:
- The mannequin receives photos as enter which can be transformed to an embedding utilizing the frozen visible encoder.
- Along with these photos, the mannequin receives their textual content descriptions, that are additionally transformed into embedding.
- The Q-Former is educated utilizing image-text contrastive loss, making certain that the visible embeddings align carefully with their corresponding textual embeddings and get additional away from the non-matching textual content descriptions. On the identical time, the image-text matching loss helps the mannequin develop fine-grained representations by studying to categorise whether or not a given textual content accurately describes the picture or not.
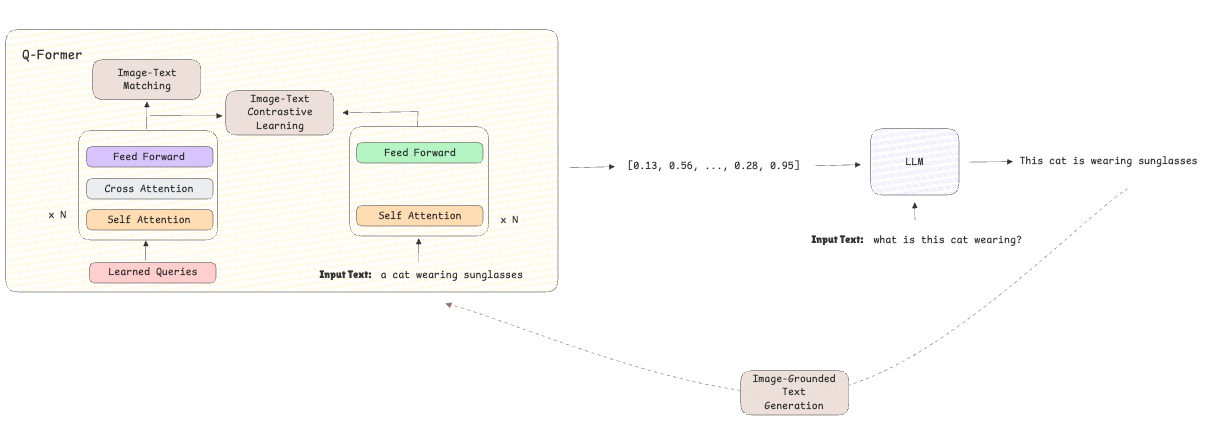
Stage 2 – Bootstrapping vision-to-language technology:
- The pre-trained language mannequin is built-in into the structure to generate textual content based mostly on the beforehand discovered representations.
- The main target shifts from alignment to textual content technology by utilizing the image-grounded textual content technology loss which improves the mannequin capabilities of reasoning and textual content technology.
Making a Multimodal Trend Search Agent utilizing BLIP-2 and Gemini
On this part, we are going to leverage the multimodal capabilities of BLIP-2 to construct a trend assistant search agent that may obtain enter textual content and/or photos and return suggestions. For the dialog capabilities of the agent, we are going to use Gemini 1.5 Professional hosted in Vertex AI, and for the interface, we are going to construct a Streamlit app.
The style dataset used on this use case is licensed beneath the MIT license and might be accessed by way of the next hyperlink: Fashion Product Images Dataset. It consists of greater than 44k photos of trend merchandise.
Step one to make this doable is to arrange a Vector DB. This allows the agent to carry out a vectorized search based mostly on the picture embeddings of the objects accessible within the retailer and the textual content or picture embeddings from the enter. We use docker and docker-compose to assist us arrange the atmosphere:
- Docker-Compose with Postgres (the database) and the PGVector extension that enables vectorized search.
companies:
postgres:
container_name: container-pg
picture: ankane/pgvector
hostname: localhost
ports:
- "5432:5432"
env_file:
- ./env/postgres.env
volumes:
- postgres-data:/var/lib/postgresql/knowledge
restart: unless-stopped
pgadmin:
container_name: container-pgadmin
picture: dpage/pgadmin4
depends_on:
- postgres
ports:
- "5050:80"
env_file:
- ./env/pgadmin.env
restart: unless-stopped
volumes:
postgres-data:- Postgres env file with the variables to log into the database.
POSTGRES_DB=postgres
POSTGRES_USER=admin
POSTGRES_PASSWORD=root- Pgadmin env file with the variables to log into the UI for handbook querying the database (elective).
[email protected]
PGADMIN_DEFAULT_PASSWORD=root- Connection env file with all of the parts to make use of to hook up with PGVector utilizing Langchain.
DRIVER=psycopg
HOST=localhost
PORT=5432
DATABASE=postgres
USERNAME=admin
PASSWORD=rootAs soon as the Vector DB is about up and operating (docker-compose up -d), it’s time to create the brokers and instruments to carry out a multimodal search. We construct two brokers to resolve this use case: one to grasp what the consumer is requesting and one other one to supply the advice:
- The classifier is answerable for receiving the enter message from the client and extracting which class of garments the consumer is on the lookout for, for instance, t-shirts, pants, footwear, jerseys, or shirts. It would additionally return the variety of objects the client desires in order that we are able to retrieve the precise quantity from the Vector DB.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Area
class ClassifierOutput(BaseModel):
"""
Knowledge construction for the mannequin's output.
"""
class: listing = Area(
description="An inventory of garments class to seek for ('t-shirt', 'pants', 'footwear', 'jersey', 'shirt')."
)
number_of_items: int = Area(description="The variety of objects we should always retrieve.")
class Classifier:
"""
Classifier class for classification of enter textual content.
"""
def __init__(self, mannequin: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
mannequin (ChatVertexAI): The LLM mannequin.
"""
tremendous().__init__()
parser = PydanticOutputParser(pydantic_object=ClassifierOutput)
text_prompt = """
You're a trend assistant knowledgeable on understanding what a buyer wants and on extracting the class or classes of garments a buyer desires from the given textual content.
Textual content:
{textual content}
Directions:
1. Learn rigorously the textual content.
2. Extract the class or classes of garments the client is on the lookout for, it may be:
- t-shirt if the custimer is on the lookout for a t-shirt.
- pants if the client is on the lookout for pants.
- jacket if the client is on the lookout for a jacket.
- footwear if the client is on the lookout for footwear.
- jersey if the client is on the lookout for a jersey.
- shirt if the client is on the lookout for a shirt.
3. If the client is on the lookout for a number of objects of the identical class, return the variety of objects we should always retrieve. If not specfied however the consumer requested for greater than 1, return 2.
4. If the client is on the lookout for a number of class, the variety of objects ought to be 1.
5. Return a legitimate JSON with the classes discovered, the important thing should be 'class' and the worth should be a listing with the classes discovered and 'number_of_items' with the variety of objects we should always retrieve.
Present the output as a legitimate JSON object with none extra formatting, reminiscent of backticks or further textual content. Make sure the JSON is accurately structured based on the schema offered under.
{format_instructions}
Reply:
"""
immediate = PromptTemplate.from_template(
text_prompt, partial_variables={"format_instructions": parser.get_format_instructions()}
)
self.chain = immediate | mannequin | parser
def classify(self, textual content: str) -> ClassifierOutput:
"""
Get the class from the mannequin based mostly on the textual content context.
Args:
textual content (str): consumer message.
Returns:
ClassifierOutput: The mannequin's reply.
"""
strive:
return self.chain.invoke({"textual content": textual content})
besides Exception as e:
increase RuntimeError(f"Error invoking the chain: {e}")
- The assistant is answerable for answering with a personalised advice retrieved from the Vector DB. On this case, we’re additionally leveraging the multimodal capabilities of Gemini to research the pictures retrieved and produce a greater reply.
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_google_vertexai import ChatVertexAI
from pydantic import BaseModel, Area
class AssistantOutput(BaseModel):
"""
Knowledge construction for the mannequin's output.
"""
reply: str = Area(description="A string with the style recommendation for the client.")
class Assistant:
"""
Assitant class for offering trend recommendation.
"""
def __init__(self, mannequin: ChatVertexAI) -> None:
"""
Initialize the Chain class by creating the chain.
Args:
mannequin (ChatVertexAI): The LLM mannequin.
"""
tremendous().__init__()
parser = PydanticOutputParser(pydantic_object=AssistantOutput)
text_prompt = """
You're employed for a trend retailer and you're a trend assistant knowledgeable on understanding what a buyer wants.
Based mostly on the objects which can be accessible within the retailer and the client message under, present a trend recommendation for the client.
Variety of objects: {number_of_items}
Photographs of things:
{objects}
Buyer message:
{customer_message}
Directions:
1. Test rigorously the pictures offered.
2. Learn rigorously the client wants.
3. Present a trend recommendation for the client based mostly on the objects and buyer message.
4. Return a legitimate JSON with the recommendation, the important thing should be 'reply' and the worth should be a string along with your recommendation.
Present the output as a legitimate JSON object with none extra formatting, reminiscent of backticks or further textual content. Make sure the JSON is accurately structured based on the schema offered under.
{format_instructions}
Reply:
"""
immediate = PromptTemplate.from_template(
text_prompt, partial_variables={"format_instructions": parser.get_format_instructions()}
)
self.chain = immediate | mannequin | parser
def get_advice(self, textual content: str, objects: listing, number_of_items: int) -> AssistantOutput:
"""
Get recommendation from the mannequin based mostly on the textual content and objects context.
Args:
textual content (str): consumer message.
objects (listing): objects discovered for the client.
number_of_items (int): variety of objects to be retrieved.
Returns:
AssistantOutput: The mannequin's reply.
"""
strive:
return self.chain.invoke({"customer_message": textual content, "objects": objects, "number_of_items": number_of_items})
besides Exception as e:
increase RuntimeError(f"Error invoking the chain: {e}")
By way of instruments, we outline one based mostly on BLIP-2. It consists of a operate that receives a textual content or picture as enter and returns normalized embeddings. Relying on the enter, the embeddings are produced utilizing the textual content embedding mannequin or the picture embedding mannequin of BLIP-2.
from typing import Non-compulsory
import numpy as np
import torch
import torch.nn.practical as F
from PIL import Picture
from PIL.JpegImagePlugin import JpegImageFile
from transformers import AutoProcessor, Blip2TextModelWithProjection, Blip2VisionModelWithProjection
PROCESSOR = AutoProcessor.from_pretrained("Salesforce/blip2-itm-vit-g")
TEXT_MODEL = Blip2TextModelWithProjection.from_pretrained("Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32).to(
"cpu"
)
IMAGE_MODEL = Blip2VisionModelWithProjection.from_pretrained(
"Salesforce/blip2-itm-vit-g", torch_dtype=torch.float32
).to("cpu")
def generate_embeddings(textual content: Non-compulsory[str] = None, picture: Non-compulsory[JpegImageFile] = None) -> np.ndarray:
"""
Generate embeddings from textual content or picture utilizing the Blip2 mannequin.
Args:
textual content (Non-compulsory[str]): buyer enter textual content
picture (Non-compulsory[Image]): buyer enter picture
Returns:
np.ndarray: embedding vector
"""
if textual content:
inputs = PROCESSOR(textual content=textual content, return_tensors="pt").to("cpu")
outputs = TEXT_MODEL(**inputs)
embedding = F.normalize(outputs.text_embeds, p=2, dim=1)[:, 0, :].detach().numpy().flatten()
else:
inputs = PROCESSOR(photos=picture, return_tensors="pt").to("cpu", torch.float16)
outputs = IMAGE_MODEL(**inputs)
embedding = F.normalize(outputs.image_embeds, p=2, dim=1).imply(dim=1).detach().numpy().flatten()
return embedding
Notice that we create the connection to PGVector with a distinct embedding mannequin as a result of it’s obligatory, though it won’t be used since we are going to retailer the embeddings produced by BLIP-2 immediately.
Within the loop under, we iterate over all classes of garments, load the pictures, and create and append the embeddings to be saved within the vector db into a listing. Additionally, we retailer the trail to the picture as textual content in order that we are able to render it in our Streamlit app. Lastly, we retailer the class to filter the outcomes based mostly on the class predicted by the classifier agent.
import glob
import os
from dotenv import load_dotenv
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Picture
from blip2 import generate_embeddings
load_dotenv("env/connection.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
consumer=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # doesn't matter for our use case
collection_name="trend",
connection=CONNECTION_STRING,
use_jsonb=True,
)
if __name__ == "__main__":
# generate picture embeddings
# save path to picture in textual content
# save class in metadata
texts = []
embeddings = []
metadatas = []
for class in glob.glob("photos/*"):
cat = class.cut up("/")[-1]
for img in glob.glob(f"{class}/*"):
texts.append(img)
embeddings.append(generate_embeddings(picture=Picture.open(img)).tolist())
metadatas.append({"class": cat})
vector_db.add_embeddings(texts, embeddings, metadatas)We are able to now construct our Streamlit app to talk with our assistant and ask for suggestions. The chat begins with the agent asking the way it can assist and offering a field for the client to put in writing a message and/or to add a file.
As soon as the client replies, the workflow is the next:
- The classifier agent identifies which classes of garments the client is on the lookout for and what number of models they need.
- If the client uploads a file, this file goes to be transformed into an embedding, and we are going to search for comparable objects within the vector db, conditioned by the class of garments the client desires and the variety of models.
- The objects retrieved and the client’s enter message are then despatched to the assistant agent to provide the advice message that’s rendered along with the pictures retrieved.
- If the client didn’t add a file, the method is similar, however as an alternative of producing picture embeddings for retrieval, we create textual content embeddings.
import os
import streamlit as st
from dotenv import load_dotenv
from langchain_google_vertexai import ChatVertexAI
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_postgres.vectorstores import PGVector
from PIL import Picture
import utils
from assistant import Assistant
from blip2 import generate_embeddings
from classifier import Classifier
load_dotenv("env/connection.env")
load_dotenv("env/llm.env")
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.getenv("DRIVER"),
host=os.getenv("HOST"),
port=os.getenv("PORT"),
database=os.getenv("DATABASE"),
consumer=os.getenv("USERNAME"),
password=os.getenv("PASSWORD"),
)
vector_db = PGVector(
embeddings=HuggingFaceEmbeddings(model_name="nomic-ai/modernbert-embed-base"), # doesn't matter for our use case
collection_name="trend",
connection=CONNECTION_STRING,
use_jsonb=True,
)
mannequin = ChatVertexAI(model_name=os.getenv("MODEL_NAME"), undertaking=os.getenv("PROJECT_ID"), temperarture=0.0)
classifier = Classifier(mannequin)
assistant = Assistant(mannequin)
st.title("Welcome to ZAAI's Trend Assistant")
user_input = st.text_input("Hello, I am ZAAI's Trend Assistant. How can I assist you to immediately?")
uploaded_file = st.file_uploader("Add a picture", sort=["jpg", "jpeg", "png"])
if st.button("Submit"):
# perceive what the consumer is asking for
classification = classifier.classify(user_input)
if uploaded_file:
picture = Picture.open(uploaded_file)
picture.save("input_image.jpg")
embedding = generate_embeddings(picture=picture)
else:
# create textual content embeddings in case the consumer doesn't add a picture
embedding = generate_embeddings(textual content=user_input)
# create a listing of things to be retrieved and the trail
retrieved_items = []
retrieved_items_path = []
for merchandise in classification.class:
garments = vector_db.similarity_search_by_vector(
embedding, okay=classification.number_of_items, filter={"class": {"$in": [item]}}
)
for dress in garments:
retrieved_items.append({"bytesBase64Encoded": utils.encode_image_to_base64(dress.page_content)})
retrieved_items_path.append(dress.page_content)
# get assistant's advice
assistant_output = assistant.get_advice(user_input, retrieved_items, len(retrieved_items))
st.write(assistant_output.reply)
cols = st.columns(len(retrieved_items)+1)
for col, retrieved_item in zip(cols, ["input_image.jpg"]+retrieved_items_path):
col.picture(retrieved_item)
user_input = st.text_input("")
else:
st.warning("Please present textual content.")Each examples might be seen under:
Determine 6 exhibits an instance the place the client uploaded a picture of a crimson t-shirt and requested the agent to finish the outfit.
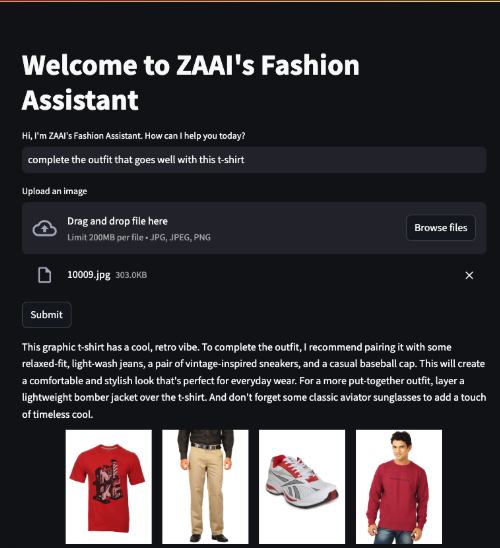
Determine 7 exhibits a extra easy instance the place the client requested the agent to point out them black t-shirts.

Conclusion
Multimodal AI is not only a analysis matter. It’s getting used within the trade to reshape the best way clients work together with firm catalogs. On this article, we explored how multimodal fashions like BLIP-2 and Gemini might be mixed to deal with real-world issues and supply a extra personalised expertise to clients in a scalable approach.
We explored the structure of BLIP-2 in depth, demonstrating the way it bridges the hole between textual content and picture modalities. To increase its capabilities, we developed a system of brokers, every specializing in several duties. This technique integrates an LLM (Gemini) and a vector database, enabling retrieval of the product catalog utilizing textual content and picture embeddings. We additionally leveraged Gemini’s multimodal reasoning to enhance the gross sales assistant agent’s responses to be extra human-like.
With instruments like BLIP-2, Gemini, and PG Vector, the way forward for multimodal search and retrieval is already occurring, and the various search engines of the long run will look very totally different from those we use immediately.
About me
Serial entrepreneur and chief within the AI area. I develop AI merchandise for companies and put money into AI-focused startups.
Founder @ ZAAI | LinkedIn | X/Twitter
References
[1] Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. 2023. BLIP-2: Bootstrapping Language-Picture Pre-training with Frozen Picture Encoders and Massive Language Fashions. arXiv:2301.12597
[2] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnan. 2020. Supervised Contrastive Studying. arXiv:2004.11362
[3] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi. 2021. Align earlier than Fuse: Imaginative and prescient and Language Illustration Studying with Momentum Distillation. arXiv:2107.07651
[4] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon. 2019. Unified Language Mannequin Pre-training for Pure Language Understanding and Era. arXiv:1905.03197
Source link